v0を使って我らが食神のメニューを必要以上にスタイリッシュにする
この記事は whywaita Advent Calendar 2023 24日目の記事です。
前日は MetaVariable さんの 型落ちゲーミングPCからはじめる自宅Kubernetes + GPU環境 でした。
さて、whywaitaさんといえば食神という、とある大学の準食堂とまで言われている有名な中華屋さんのメニューをデジタル化していることで定評があります。 今回はこのデータを今流行りの生成系AIを用い、メニューの可視性を向上させてみようという試みを実施します。
肝心のデータは ここ にありますので、まずはgit clone しましょう。 データは定番メニューと限定、日替わり定食などと別れているのでそれぞれ開いてみると以下の用になっているかと思います。以下はfixed.csvに格納されているメニューです。
id,name,price,category,day_start,day_end,can_weekday,description 1,麻婆豆腐,650,定食,,,,1番 2,豆腐のうま煮,650,定食,,,,2番 3,肉野菜炒め,650,定食,,,,3番 4,豚肉とザーサイの細切り炒め,650,定食,,,,4番 5,麻婆春雨,650,定食,,,,5番 6,かに玉子,650,定食,,,,6番 7,ニラ玉子,650,定食,,,,7番 8,玉ねぎと玉子炒め,650,定食,,,,8番 9,豚肉と玉ねぎの生姜焼き,780,定食,,,月,月曜11番 .....
はい。非常に美味しそうですね。食べたい。
私の母校も実はこのとある大学なのですが、当時はサークルのメンバーに誘われよく食神に赴いており、大体4番の豚肉とザーサイの細切り炒めを注文しておりました。付属のスープに春雨を入れる派でした。
データセットがそろったので、本題の加工に入っていきたいと思います。可視化の向上の定義をちゃんと話すと永遠と出来ると思いますので、今回は見た目の向上に限って言及していきます。
v0.devというのをご存知でしょうか?Next.jsの開発元のVercelが発表した生成系AIを用いた対話式のUI生成SaaSです。Tailwind CSSとShadcn UIをベースにコードを生成してくれるようです。 長らくWaitinglistに登録したまましばらく忘れていたのですが、先日めでたく『You now have access to v0 by Vercel』のメールと共に利用可能になったので、使っていきたいと思います。
v0を開くと以下のように入力欄と、今まで生成されたUIがタイル表示された画面に遷移すると思います。

UIを作ってもらうために、プロンプトを打つのですが、CSVからフードメニューのダッシュボードを作って欲しいので、まずは『csv datasource dashboard for cuisine menu』と入力してみました。
cuisineは郷土料理という意味が強いので厳密にはズレるのですが、まあ町中華は郷土料理みたいなものなので今回は良しとしましょう。
しばらく待つとUIが出来てました。1回に3パターン生成されるのがデフォルトのようです。ちょっとずつそれぞれのUIが出来てくるのはタイムラプスを見ているような感覚になりますね。

いくつか生成を試した所、面倒くさくなったまあ良いのではと思えるのが合ったので実際に利用してみようと思います。v0はあくまでNext.jsのコンポーネントとして出力してくれるのみなので、大元のプロジェクトが必要になります。ひとまずプロジェクトを作成しましょう。
プロジェクトを作成した後、v0でinitし、既存のプロジェクトでv0を利用出来るようにします。その後生成したコンポーネントを利用するため、v0 addを実施する必要があります。
以下コマンドでVercelプロジェクトをセットアップ出来ます。vercel init した際にどのフレームワークを利用するか聞かれますが、v0が現状Next.js対応のみなので、nextjsを選択しましょう。
$ npm install -g vercel $ vercel init
生成したコンポーネントの画面の右上部に code というボタンがあるのでクリックし、add コマンドを取得します。

以下のコマンドでコンポーネントを取得します。以下コマンドで私が今回生成し利用するコンポーネントを取得することが出来ます。
$ npx v0 add F3KMrbPfT1s
すると先程のコードが components 配下に、export function された状態で生成されます。これを適宜pagesディレクトリにページを作成し、コンポーネントを呼んであげましょう。
npm run dev すると、以下の用にページがレンダリングされました。

利用出来るようになったのはいいのですが、肝心のcsvを読みに行かなければなりません。csvを読みコンポーネントを生成する関数をつくります。 今回は認証もなく、ただデータを取りに行くだけなので、コンポーネント内部から直接httpリクエストを投げちゃいます。
無事コンポーネントが生成され、実データが反映出来ました。

本当は商品画像もほしい所ですが実データが手元にないので今回はno imageな画像で代替しています。
今回作成したコードはこちらのリポジトリに格納しています。絞り込み検索もつけたかったのですが、うまく行かず。うまく行ってないコードをbranch切って上げてありますので興味ある方は暇つぶしに是非(笑)
生成系AIによって我々の環境は大きく変わりました。今まで出来なかったことが出来るようになり、直面する課題はより高度になっていきます。ですが本質は変わらないので楽しんで適応できればとおもいます。
※私はNext.jsはおろかVercelもほぼ初めて(TypeScriptは新卒2年目以降書いてない浦島太郎)の状態なのですが、CopilotやCursorのGPT-4を使いつつ、対話し学習しながらこれを作成しました。本当強力な右腕&教育係みたいな感じで、出来なかったことが出来るようになるのは楽しいですね。この記事で本当に伝えたいことは生成系AIが自分の能力をExtendしてくれることの凄さかもしれません。
さて明日の whywaita Advent Calendar 2023 はいよいよ我らがwhywaitaさんです!!!
Kubernetes1.13ぶりに触ったおじさんの復活記
この記事は Kubernetes Advent Calendar 2023 の15日目の記事です。
目次
- これは何?あなたは?
- 復活する前は何をしていたの?
- 復活するきっかけは?
- 復活するにあたって
- で、復活できたの?
これは何?あなたは?
会社員になって8年目くらいの三十路突入おじさんの(エンジニア)復活記(ポエム)です。
某緑色の会社(今は黒のイメージもあるかも?)でエンジニアをしています。入社時はバックエンド採用&子会社出向でしたが紆余曲折し、現在は親会社に戻りプライベートクラウドでKaaS基盤開発に従事しています。
復活する前は何をしていたの?
復活する前はテクニカルコンサルタントとして、子会社の事業開発の技術面で横断的にサポートする役割を担っていました。
仕様書策定やスケジュール管理、外部の開発会社との打ち合わせで、いわゆる上流工程の仕事を担当することが多かったです。事業開発に重きをおいていたので市場調査やPL等の作成も一部担当していました。
もっと遡ると、動画配信サービスのパブリッククラウドのインフラエンジニアをしていたので、その流れでサーバー構築などの業務も担当していました。
復活するきっかけは?
入社時は技術指向が強かったのですが、事業開発において技術で解決出来る問題の幅の限界を痛感することがあり、そこから事業計画や組織計画に興味を持つようになりました。
その延長でテクニカルコンサルタントに2~3年従事していたのですが、外部の開発会社(案件の性質上オフショアが多かったってのもあります)を利用するため、納品形式や運用面を考えると、どうしても技術的に枯れたアーキテクチャを採用せざるを得ないことがほとんどでした。
またコンサルタントという名前がついている以上ビジネス的な知識理解のキャッチアップも必須です。
これに加えて、最新の技術をキャッチアップ、自分で手を動かして検証といったことをプライベート含めてやっていくのが、業務が比較的多忙だったという言い訳をする形になるのですが、難しくなっていたのが実情です。
新しい技術から取り残された焦燥感があったこと、担当していたいくつかの事業開発も会社の状況変化、市況感の変化により規模縮小や開発凍結になることがあり厳しさを感じており、
三十路突入し新しい事にチャレンジするにはちょうどよい機会かもと思っていたのも重なりました。
異動自体は社内の異動制度を利用し比較的スムーズに異動することが叶いました。制度が整備されている弊社に感謝感激という感じです。
復活するにあたって
業務コードを書くことから離れて6年弱、チーム開発から離れて2~3年程度の人間がいきなり最新鋭のKaaS基盤開発にジョインするに当たってもちろんスキルのギャップがあるわけですが、この差を埋める必要が出てきます。
復活前のスキルは以下のような状態でした。
- パブリッククラウドインフラ(AWS)
- 中~大規模サービスのアーキテクティング&運用経験
- AnsibleやCloudFormationを用いた自動化
- Python, Rubyを用いたツール開発
- 機能要件、非機能要件を仕様書に落とし込み開発会社選定し、開発を進める
- 開発進捗管理
KaaS開発では以下のスキルが求められていました。
- Kubernetesの思想Kubernetesそのものに対する深い知識、周辺エコシステムの知識
- オンプレミスで用いているアプライアンスの基本的な知識
- go言語のスキル
- カスタムコントローラの知識
未経験のものが多く、かつスキルギャップがかなりあり、Kubernetes自体も1.13から触っておらずCRDもGA前だったので知らずで、浦島太郎もびっくりの何も分からん状態からのスタートでした。
この状態でも受け入れてくれた今の事業部には本当感謝しかありません。 ギャップを埋めるために以下のことを実施しました。
- Kubernetesに触る絶対時間を増やす
- 最新情報のキャッチアップの時間を強制的に増やす
- 自分で手を動かして開発する感覚を取り戻すために、趣味開発を再開する。goでなるべく書く
Kubernetesに触る絶対時間を増やす
当たり前ですが、実際に手を動かさないと知識は血肉になりません。Kubernetes自体を理解したかったことと、ランニングコストを低く抑えたいなどを考えた結果、ミニPCにUbuntuを入れmicroK8sやk0sなどのディストリビューションを用いて構築するのが良いだろうとなり、N100とメモリ16GBが搭載されたミニPCを購入し自宅で稼働させることにしました。
VPNも張ってどこからでもアクセス出来るようにし、いつでもどこからでも同一のクラスタを触れるようにしました。
また好きこそものの上手なれと言われるように、自身の興味関心の方向と合わせた方が知識習得も早いと考え、今までAnsibleでVMにセットアップしていたような内容もKubernetesのマニフェストを書いたりし、昔書いていたwebAPIをDeploymentにしてみたり等を実施しました。
最新情報のキャッチアップの時間を強制的に増やす
現チームで既に行っていたKubernetesキャッチアップ会と呼ばれる、LWKDとKubeweeklyを読む時間のファシリテーションを任せてもらいました。
事前に読んでおき、関連するKEPやわからない所を調べるようにしていましたが、比較的マイナーなリソースや、前提知識が必要となる内容はやはり理解の解像度が低かったため、メンバーに質問し解答をもらったりを繰り返しました。
自分で手を動かして開発する感覚を取り戻すために、趣味開発を再開する。goでなるべく書く
前述の通り、単一または少数で終わるようなスクリプトはずっと書いていましたが、サービスやソフトウェアとみなされる単位での開発は久しくしていませんでした。
自身で考えた設計を自身で作り切り、運用することが重要なので、趣味でもサービス開発を再開することにしました。たまたまタイミングよく旧友に声をかけてもらい、内々で使う分析ツールを作ることにしました。
これがかなり効果的でgo言語の習得速度の向上に寄与しました。手に馴染むという表現が合っているかは分かりませんが、やりたいことや実現したいことはまあ実装出来るだろうという自信に繋がりました。
(余談ですが、goの知識習得にはchatGPTやGitHub Copilotが大いに貢献してくれました。新しい事の学習にはもってこいだと思います本当に)
業務では、大きなものではKubernetesのカスタムコントローラーを開発するタスクを担当することになりました。
RBACと監査ログを利用する内容なのですが、Role/ClusterRoleはもちろんKubernetesのよく出てくるリソースの理解も曖昧だったので、チームメンバーに1on1やレビューをお願いし、その過程で知識を深めていく形になりました。
最初からカスタムコントローラーの開発はスキル的に厳しかったので、一旦はCLIのようなものを作り計算処理部分の考え方や基本的なgoの知識などを確認してもらいました。
必要があればKubernetesや周辺ソフトウェア自体のソースコードを読んだり、Upstreamにコントリビュートするのが文化として根付いているチームのおかげもあり、私も自然とそのような動きが出来るようになっていきました。
で、復活できたの?
半年あればその業界のトップランカーになる人も少なくない中、そのようなレベルの復活は成し遂げられなかった事は事実です(まあそこは高望みしすぎですがw)
そこまでいかず、Kubernetes、CloudNativeを利活用し、適切なアーキテクチャ提案、実装が出来るかを復活の定義だとしても、正直まだまだです。
ですが、KubernetesのReconcileの設計の美しさ、Kubernetesを通して様々なものをas a Serviceとして開発出来る可能性の広さに改めて感銘を受け、利用していかない手は無いという感覚になれたことは非常に大きいと考えています。業界の流れも早く生成AIの兼ね合いもありデファクトはどんどん変わっていきます。
コンサル自体からやっていた、時流を読み都度適切な情報収集をし最大効果をもたらす動き、を活かしつつ、エンジニアリングに関してもたゆまず成長していければと考えています。
任意の型を引数に取り、そのフィールドの値を集計して返す
業務で利用しようとし、実装したのですがPerformance Issueにより不使用にしたので供養がてらブログネタとします。
type Fruits struct { Apple float32 Banana float32 Orange float32 Strawberry float32 Raspberry float32 Kiwi float32 Coconut float32 Papaya float32 Grapefruit float32 Avocado float32 }
のような構造体があるとします。float32には価格が格納されています。また、この構造体は追加・削除がそこそこ発生します。 この時Fruits全体の合計値を知りたいと思った時、愚直に足し算を実装しても良いのですが、構造体の追加・削除が発生した時に実装の修正が必要になります。
これは少々煩雑なので、Fieldの数に依存せずに合計を計算出来ないかと考え、Reflectionを利用してFieldのValueを取得する関数を作ってみました。
(結構Copilotが作ってくれた)
func FruitsAllWithType(s interface{}) []float32 { v := reflect.ValueOf(s) typeOfS := v.Type() scores := make([]float32, v.NumField()) for i := 0; i < v.NumField(); i++ { fieldName := typeOfS.Field(i).Name fieldValue := v.FieldByName(fieldName).Interface() if value, ok := fieldValue.(float32); ok { scores = append(scores, value) } } return scores }
任意のstruct sをfor文でひたすら回して、逐次Fileld名を取得し、そのField名でValueをInterfaceとして取り出し、型がfloat32であればsliceに追加するという実装です。 以下で試すことができます go.dev
この実装は前述の通りPerformance Issueがあるため不使用としました(まあそもそも map[string]float32 のほうが利便性含め良くないかってこともあったんですが)
先ほどの関数をgo標準のtesting packageにあるbenckmarkを利用して、計算時間を計測しました。 10種類のFields及びmap[string]float32の足し合わせを100万回ループさせた時の測定結果です
goos: darwin goarch: arm64 BenchmarkCalCAllFruitPrice1-12 1000000000 1.056 ns/op BenchmarkCalCAllFruitPrice2-12 1000000000 0.08979 ns/op PASS ok 70.150s
- BenchmarkCalCAllFruitPrice1-12: Fieldを集計したもの
- BenchmarkCalCAllFruitPrice2-12: mapを集計したもの
1ベンチマークループで10.6倍程度の差が付きました。 動的に処理することや毎回の型検査が入ってくるのでパフォーマンスに大きな影響が出ていることが分かります。
オンラインのワークロードではない、速度を重要視しない内容や、非構造なデータを扱う時にReflectionは力を発揮するので、用法用量を守って利用しましょう。
参考
auditlogを出力出来るようにして、promtailでパースしてlokiに送信してみる
現在Kubernetesの証跡ログ(auditlog)周りを業務で扱っており、思ったより情報がなかった(もしかしたら基本なことなので書くまでも無いってこともありますが。。)ので記事にしてみようと思います。 以下寄り証跡ログのことをauditlogとして表現します。
Kubernetesのauditlogはデフォルトでは出力されず、kube-apiserverの起動時にパラメータを追加して起動してあげる必要があります。ここまでは割と事例があるので割愛します。 auditlogの出力ポリシーはGoogle Container-Optimized OSの監査プロファイルを参考に構築すれば大丈夫です。具体的にはconfigure-helper.shのスクリプトに書かれているのでこちらを参考にします。
今回はkubernetesをLimaVMで構築し、auditlogを有効化したクラスタの上で作業してみます。クラスタ自体はLimaVMのプリセットで存在する k8s を利用します。VM自体の起動コマンドは以下になります。
VM名は k8s としていますが、それ以外はデフォルト値で上がってきます。CPU: 4コア, メモリ: 4GB, ルートボリューム100GBのVMが出来上がるかと思います
$ limactl start --name=k8s template://k8s
このKubernetesクラスタはkubeadmで構築されており、kube-apiserverのマニフェストなどは /etc/kubernetes/manifests/kube-apiserver.yaml に存在しており、起動時のオプションもここに記述する必要があります。
またauditlogを格納するボリュームのマウント、audit-policy.yamlもconfigとしてマウントしてあげる必要があるため、volumeMountなどの記載も必要になります。
brバニラで起動したkuberenetesクラスタのkube-apiserver.yamlをのdiffは以下のようになります。
diff <(limactl shell k8s-vanilla -- sudo cat /etc/kubernetes/manifests/kube-apiserver.yaml) <(limactl shell k8s -- sudo cat /etc/kubernetes/manifests/kube-apiserver.yaml) 43c43,48 --- > - --audit-log-path=/var/log/kubernetes-audit/audit.log > - --audit-policy-file=/etc/kubernetes/manifests/audit-policy.yaml > - --audit-log-maxsize=100 > - --audit-log-maxbackup=10 > - --audit-log-maxage=7 93a99,104 > - mountPath: /etc/kubernetes/manifests/audit-policy.yaml > name: audit > readOnly: true > - mountPath: /var/log/kubernetes-audit > name: audit-log > readOnly: false 119a131,138 > - hostPath: > path: /etc/kubernetes/manifests/audit-policy.yaml > type: File > name: audit > - hostPath: > path: /var/log/kubernetes-audit > type: DirectoryOrCreate > name: audit-log
設定が問題なければ、kube-apiserver.yamlの保存ととともに、ファイルの変更をkubeletが検知して自動でkube-apiserverが再起動しauditlogを出力する状態になったクラスタが立ち上がります。 設定のどこかに問題があればkube-apiserverが再起動を繰り返すので、kube-apiserverやkubeletのログを確認しましょう。
上記の設定にしていれば、auditlogは /var/log/kubernetes-audit/audit.logに出力されます。中はJSON形式になっており、出力されている量が多ければ100MB毎にローテートされているはずです。
出力されている内容の一部を切り出すと以下の内容になっていました。
{ "kind": "Event", "apiVersion": "audit.k8s.io/v1", "level": "Metadata", "auditID": "b6bf51ff-9ea1-40d8-98bb-a95b2a2ccd21", "stage": "ResponseStarted", "requestURI": "/api/v1/namespaces/kube-system/configmaps?allowWatchBookmarks=true&fieldSelector=metadata.name%3Dextension-apiserver-authentication&resourceVersion=655053&timeout=8m13s&timeoutSeconds=493&watch=true", "verb": "watch", "user": { "username": "system:kube-scheduler", "groups": [ "system:authenticated" ] }, "sourceIPs": [ "192.168.5.15" ], "userAgent": "kube-scheduler/v1.26.2 (linux/amd64) kubernetes/fc04e73", "objectRef": { "resource": "configmaps", "namespace": "kube-system", "name": "extension-apiserver-authentication", "apiVersion": "v1" }, "responseStatus": { "metadata": {}, "code": 200 }, "requestReceivedTimestamp": "2023-04-02T03:32:36.682654Z", "stageTimestamp": "2023-04-02T03:32:36.685631Z", "annotations": { "authorization.k8s.io/decision": "allow", "authorization.k8s.io/reason": "RBAC: allowed by RoleBinding \"system::extension-apiserver-authentication-reader/kube-system\" of Role \"extension-apiserver-authentication-reader\" to User \"system:kube-scheduler\"" } }
これらをPromtailで読み取るためにはscrape_configを作成する必要があります。JSONなのでpipeline_stagesでJSONを利用します。 k=vとなっている要素に対しては以下のように記述し、
- json:
expressions:
kind: kind
apiVersion: apiVersion
要素が更にネストしている場合は再帰的にparseしてあげる必要があるので、sourceで指定して再帰的に読み取るような設定の追加が必要になります。例えば objectRefは要素が {k: {k: v}} のようになっているため、
- json:
expressions:
objectRef:
- json:
expressions:
resource: resource
namespace: namespace
name: name
apiVersion: apiVersion
source: objectRef
のような記述が必要となります。 記載が完了し、うまくauditlogをparse出来るようになっていれば、lokiにpromtail経由でlokiにデータが蓄積されるようになっているはずです。 今回はGrafana、Loki、Promtailに関して以下のチャートを利用しました。GrafanaとLokiに関してはLoki-Stackを用いて、Promtailだけは別立てしてLoki-Stackで構築したLokiにデータをpushする形を取っています。
問題なくデータがpushされていれば、GrafanaからデータをExprole出来るようになっているかと思います。Loki-Stackに同梱されているGrafanaを用いると無事表示されているのを確認出来るかと思います。

Promtailのscrape_configも無事Fieldsとして認識しているようです

ローカルに複数のKubernetesクラスタを立てて切り替える
1年以上ぶりの記事投稿。 部署を異動して業務内容が変わり、久しぶりにKuberneresガッツリ触ることになるのでリハビリがてら記事を作成します。同じようなことやっている人は数多居るけれど気にしないスタンスで
Kubernetesをローカルで簡単に構築することができるようになって久しいです。 内容によっては複数の構成の違うKubernetesクラスタを構築してmanifestを適用して挙動の差異をみたいというモチベーションがあるかもしれません。 手元のPCはMacなので、今回はLimaとMultipassを利用してクラスタを構築し、それぞれをローカルのkubecltから切り替えて使えるところまでやってみます
※Ubuntuの世界に持ち込んで楽をしているのがお分かりかと思いますが気にしてはなりません
やること
Limaを用いてクラスタを構築
Limaはテンプレートを食わせてあげてVMを構築することができるのですが、プリセットで豊富なテンプレートが既にあります。
テンプレート一覧は limactl start --list-templates で表示可能です。表示させてあげるとk3sとk8sが出てきますので、今回はk8sの方を利用していきます。
起動コマンドは以下の通り。VM名はわかりやすくk8sとしておきました
$ limactl start --name=k8s template://k8s
実行すると以下のウィザードが出てきますので Proceed with the current configuration で構築を進めます。ウィザードが煩わしい、shellscript等で完全自動化したい場合は --tty=false オプションをつけましょう
$ limactl start --name=k8s template://k8s ? Creating an instance "k8s" [Use arrows to move, type to filter] > Proceed with the current configuration Open an editor to review or modify the current configuration Choose another example (docker, podman, archlinux, fedora, ...) Exit
構築が進行します。しばらく時間がかかるので待ちましょう。
構築が完了すると、以下の表示がされるのでkubeconfigの場所をメモっておきます(このタイミングで export KUBECONFIG="/Users... 実行しても構いません)
INFO[0459] Message from the instance "k8s": To run `kubectl` on the host (assumes kubectl is installed), run the following commands: ------ export KUBECONFIG="/Users/doridoridoriand/.lima/k8s/copied-from-guest/kubeconfig.yaml" kubectl ... ------
Multipassを用いてクラスタを構築
Mutipassは multipass find コマンドで minikubeのテンプレートイメージが既に公開されています。こちらを利用してもよいですし、snapからKubernetesをインストールしてもよいです。
今回はsnapからmicrok8sをインストールして利用してみましょう。以下のようなcloud-initを書いて、cloud-config.yml として保存しましょう
# cloud-config
# resolv.conf
manage_resolv_conf: true
resolv_conf:
nameservers: ['1.1.1.1']
# package
package_update: true
package_upgrade: true
snap:
commands:
00: snap install microk8s --classic
01: snap install kubectl --classic
runcmd:
- [ sudo, usermod, -a, -G, microk8s, ubuntu ]
- [ /snap/bin/microk8s.enable, dns, dashboard, metric-server ]
以下コマンドで構築します。Limaで構築したスペックと合わせてメモリ4GB、CPU4コアとしました
$ multipass launch --cpus 4 --disk 100 --mem 4GB --name k8s --cloud-init cloud-config.yml;
構築が完了すると Launched: k8s と表示されます。表示されたら以下コマンドでkubeconfigを取得します。
Limaと違いボリュームマッピングしてないのでローカルに保存されず、VMにコマンドを実行して取得する必要があります
$ multipass exec k8s -- /snap/bin/microk8s config view
それぞれのkubeconfigをマージ
$KUBECONFIG変数を用いるパターン、--kubeconfigオプションを用いるパターンなどがありますが、少々面倒なので2つのkubeconfigをマージしてしまいましょう。
kubeconfigの要素を抜き出すと以下のようになります
apiVersion: v1
clusters:
- cluster:
...
contexts:
- context:
...
current-context:
kind: Config
preferences: {}
users:
- name: admin
...
ここで clusters 、contexts 、usersがリスト型になっているので、それぞれのクラスタで作成したkubeconfigを並べて書いてあげればよさそうです
apiVersion: v1
clusters:
- cluster:
...
- cluster:
...
contexts:
- context:
...
- context:
...
current-context:
kind: Config
preferences: {}
users:
- name: admin
...
- name: admin
...
実際に挙動を見てましょう。分かりやすさと操作性の向上の観点から kubectx コマンドを利用しています
$ kubectx kubernetes-admin@kubernetes microk8s
無事2つ表示されました。今は上の kubernetes-admin@kubernetes が選択されている状態です。kubectlコマンドを実行してnodeの差異を見てみましょう
$ kubectl get nodes NAME STATUS ROLES AGE VERSION lima-k8s Ready control-plane 20h v1.26.2
Lima側のnodeが表示されました。次にcontextを切り替えてMultipass側のクラスタを見てみましょう
$ kubectx microk8s Switched to context "microk8s" $ kubectl get nodes NAME STATUS ROLES AGE VERSION k8s Ready <none> 3h12m v1.26.1
Multipass側のnodeが表示されました。これでローカルで複数のクラスタを構築し、切り替えて利用できるようになりました。 ローカルのマシンパワーの問題はありますが、サクッと構築できるので諸々検証が捗りますね
GUIのUbuntuを手っ取り早く用意する方法
開発の関係でササッとGUIが使えるLinux環境を用意する必要があり、忘備録がてらブログに起こしました。Macで実行しましたが、Windowsでも問題なく実行できると思います。
事前にMutipassをインストールしておいてください。
※1年以上ぶりの更新になってしまいました。。あっという間過ぎて草
とても簡単で、このフォーラムに書いてあることを実施すればOKです。
cloud-init.yml経由でubuntuを初期設定していること、ubuntuユーザー以外で実行したかったことから、cloud-config.ymlを用意して実施しました。
# package
package_update: true
package_upgrade: true
packages:
- ubuntu-desktop # enable GUI
- xrdp # connect via RDP
users:
- name: ユーザー名
groups: admin
sudo: ALL=(ALL) NOPASSWD:ALL
shell: /bin/bash
chpasswd:
list: |
ユーザー名:パスワード
expire: False
以上のファイルを cloud-config.yml として保存し、Multipassでの起動時にオプションとして渡してあげます。
- CPU4コア
- メモリ6GB
- ディスク128GB
- マシン名ubuntu-desktop
として作成します。
$ multipass launch --cpus 4 --disk 128GB --mem 6GB --name ubuntu-desktop --cloud-init cloud-config.yml
ubuntu-desktopのインストールにかなり時間が掛かりMultipassがタイムアウトのエラーを吐きますが、裏で順調にインストールが続いているのでそのまま待ちます。 作ったVMにログインし、psコマンドなどを使ってインストールプロセスの有無を確認しても良いかもしれません。
作成後、Multipassのlistコマンドを利用して、払い出されているIPを確認します。このIPはマシン内部でのみ有効です。
$ multipass list Name State IPv4 Image ubuntu-desktop Running 192.168.64.9 Ubuntu 20.04 LTS
Remote Desktopクライアントをホストにインストールし、接続してみます。Microsoft公式のクライアントが一番良いのでAppStoreからインストールします。
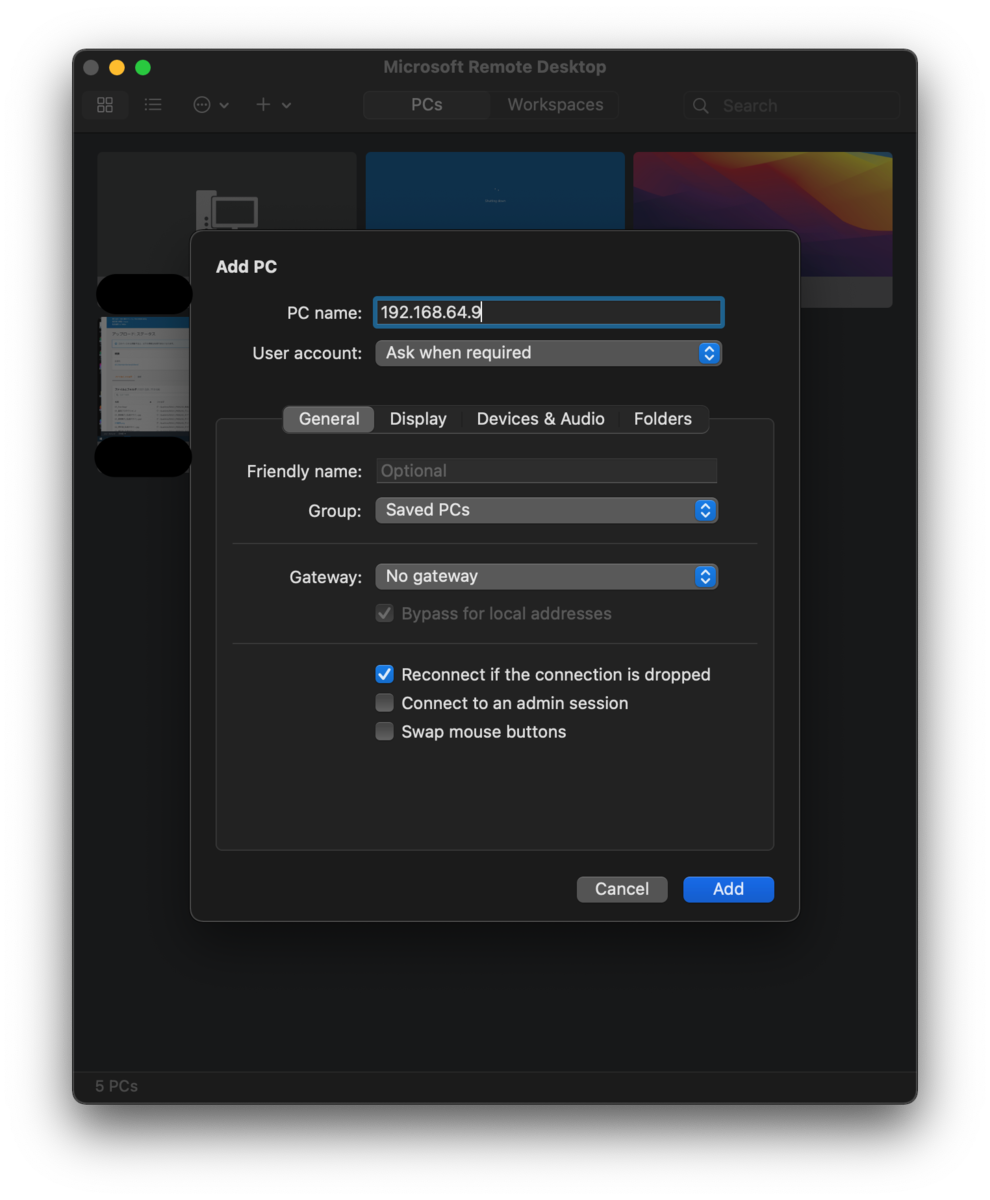
Add PC を選択し、先程取得したIPアドレスを PC name: に入力し、Add ボタン押下でPCを追加します。
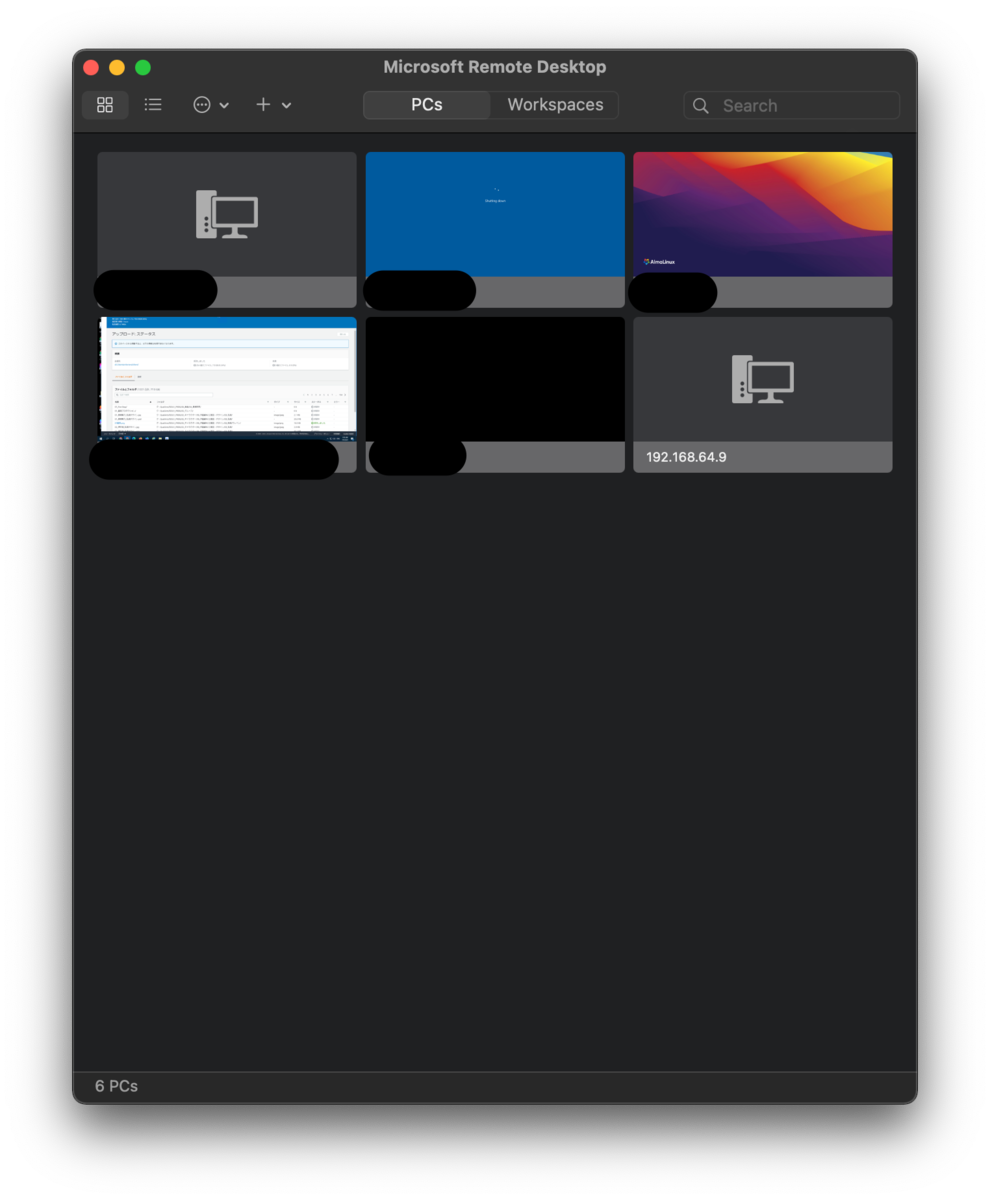
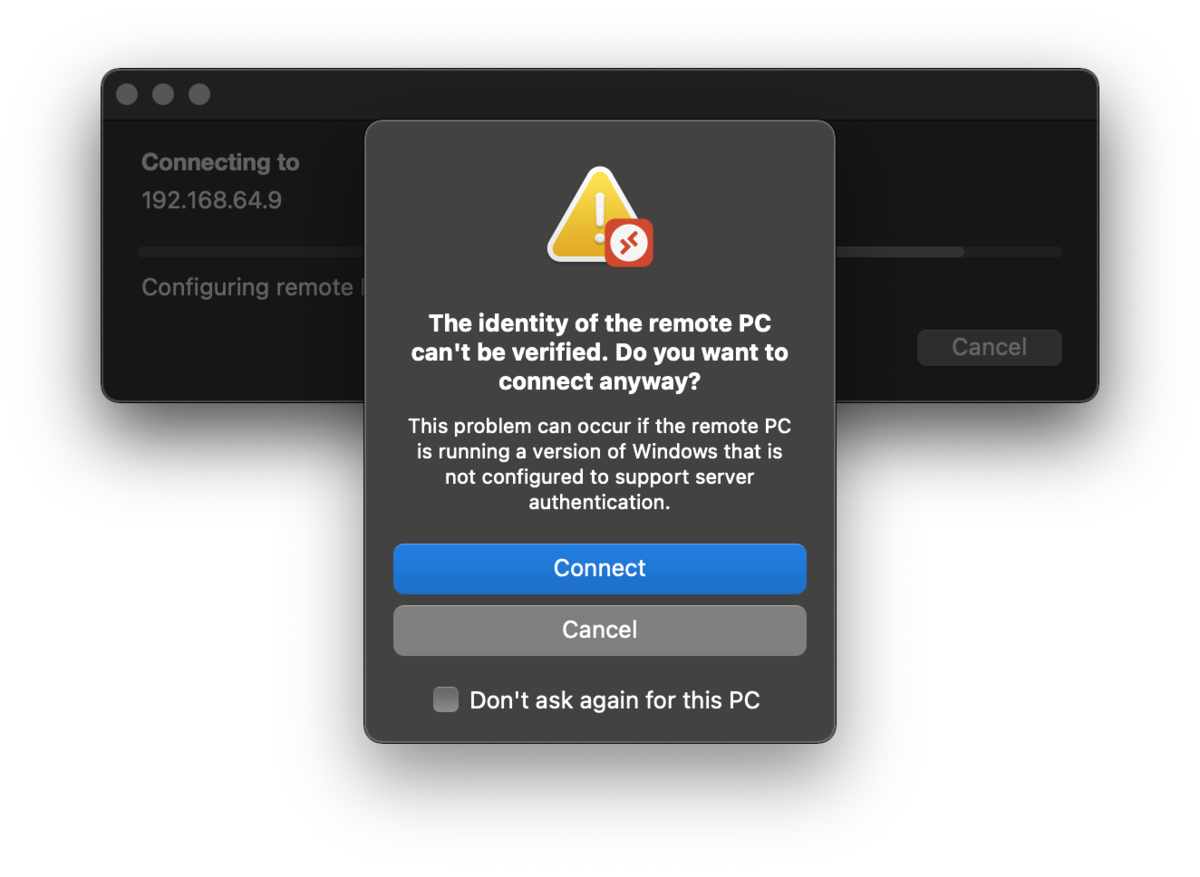
connect を押下します。
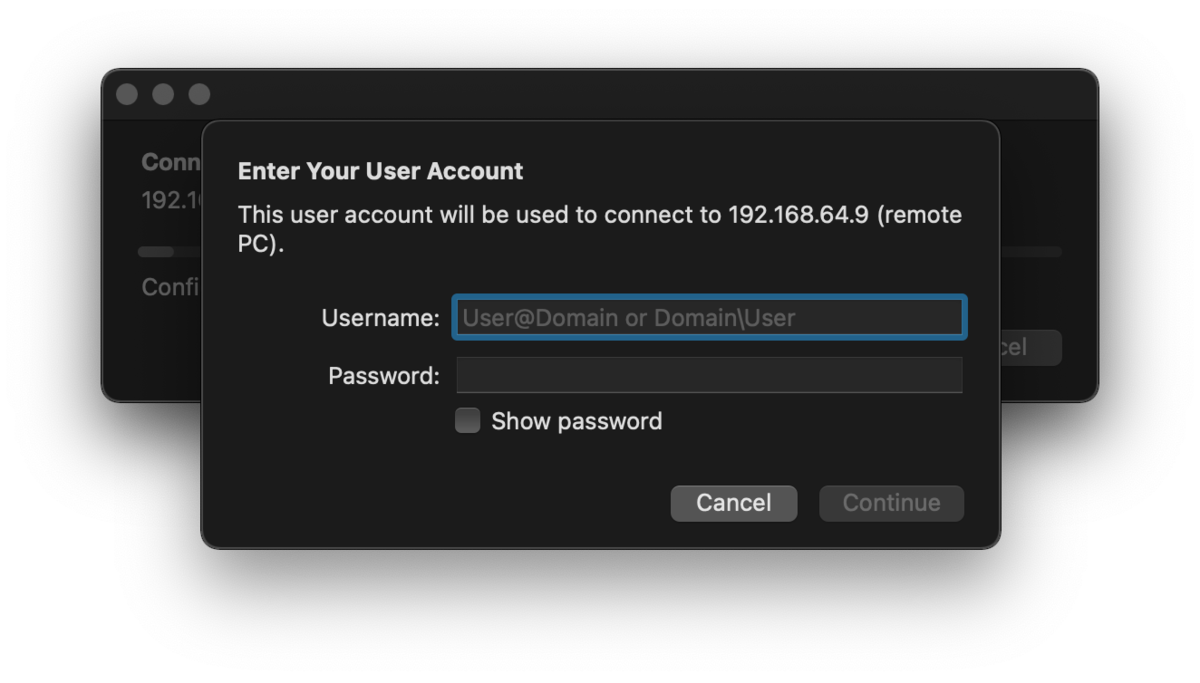
continue を押下します。
Docker Buildxを利用してマルチアーキテクチャなdockerコンテナを作成する
classmethod 若槻さんの記事 Dockerのマルチアーキテクチャイメージについて調べてみた を読んでマルチアーキテクチャなdockerコンテナを作ってみたくなったので、忘備録として記事を書きます。
ビルドの方法が分からなかったので、dockerの公式サイトを覗くと記載がありました。 Leverage multi-CPU architecture support
Docker Official Imagesの githubリポジトリ を覗くと、対応しているアーキテクチャは2020年4月12日時点で
- ARMv5 32bit (arm32v5) ※非公式
- ARMv6 32bit (arm32v6)
- ARMv7 32bit (arm32v7)
- ARMv8 64bit (arm32v8)
- Linux86-64 (amd64)
- Windows x86-64 (windows-amd64)
- IBM POWER8 (ppc64le) ※非公式
- IBM z Systems (s390x) ※非公式
- x86/i686 (i386) ※非公式
AWSが提供しているa1インスタンスのcpuinfoを見てみると
$ cat /proc/cpuinfo processor : 0 BogoMIPS : 166.66 Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid CPU implementer : 0x41 CPU architecture: 8 CPU variant : 0x0 CPU part : 0xd08 CPU revision : 3
と表示されました。ARMのドキュメントを検索すると次のページがヒットしました
ARM Information Center
このページ書かれている内容から、
CPU implementer : 0x41 => ARM Limited. CPU part : 0xd08 => Cortex-A72 processor.
ということが分かりました。Cortex-A72はARMv8アーキテクチャを採用しているCPUなので、問題なくマルチアーキテクチャビルドのコンテナが動くはずです。検証環境が整うことがわかったので今回は、
を実施してみようと思います。
前準備
exprimental featureの有効化
マルチアーキテクチャのコンテナビルドのためには experimental feature(試験的な機能)を有効にする必要があります。Docker Desktopでは、

のように config.json を記載するエリアがあるので、 Use the Docker command line | Docker Documentation に記載されているJSONを入力します。
もしくは、ホームディレクトリ直下の .docker ディレクトリに config.json があるので、同様の内容を記載すればおkです(Linuxでも同じです)。
buildKitのインストール
今回使用する buildx というプラグインは Moby BuildKit の拡張であるため、BuildKitのインストールが必要になります。
Macであれば
$ brew install buildkit
でもいいですし、公式に則った形でバイナリを /usr/local/bin 配下に設置してもいいでしょう。 buildctl コマンドが通ればインストール完了です。
$ buildctl NAME: buildctl - build utility USAGE: buildctl [global options] command [command options] [arguments...] VERSION: v0.7.0 COMMANDS: du disk usage prune clean up build cache build, b build debug debug utilities help, h Shows a list of commands or help for one command GLOBAL OPTIONS: --debug enable debug output in logs --addr value buildkitd address (default: "unix:///run/buildkit/buildkitd.sock") --tlsservername value buildkitd server name for certificate validation --tlscacert value CA certificate for validation --tlscert value client certificate --tlskey value client key --tlsdir value directory containing CA certificate, client certificate, and client key --timeout value timeout backend connection after value seconds (default: 5) --help, -h show help --version, -v print the version
buildxプラグインの追加
次に buildx というプラグインが必要になるので、 リポジトリ から最新のバイナリをダウンロードします。
ホームディレクトリにある .docker ディレクトリに cli-plugins というディレクトリを作成し、先程ダウンロードしたバイナリ docker-buildx という名前で保存します。
更に実行権限を付与します。
$ chmod a+x ~/.docker/cli-plugins/docker-buildx
以上が終わって、docker buildx コマンドが通れば利用可能です。
$ docker buildx Usage: docker buildx COMMAND Build with BuildKit Management Commands: imagetools Commands to work on images in registry Commands: bake Build from a file build Start a build create Create a new builder instance inspect Inspect current builder instance ls List builder instances rm Remove a builder instance stop Stop builder instance use Set the current builder instance version Show buildx version information Run 'docker buildx COMMAND --help' for more information on a command.
ビルド
今回は、rubyで実行したら実行マシンの現在時間を出力するコンテナを利用します。Dockerfileは以下の内容を利用します。
FROM ruby:2.6.3 CMD ruby -e "puts Time.now"
普通にビルド&実行をしてみると
$ docker build -t multi-arch-norm -f multi_arch_Dockerfile . Sending build context to Docker daemon 2.048kB Step 1/2 : FROM ruby:2.6.3 ---> d529acb9f124 Step 2/2 : CMD ruby -e "puts Time.now" ---> Running in f6ca4f8d0f5b Removing intermediate container f6ca4f8d0f5b ---> 7a130a088630 Successfully built 7a130a088630 Successfully tagged multi-arch-norm:latest $ docker run -it --rm multi-arch-norm 2020-04-12 12:15:34 +0000
と問題なく実行出来ること分かりました。
ではマルチアーキテクチャモードでビルドを実行してみます。
docker buildx build --platform linux/amd64,linux/arm64,linux/arm/v7 -t doridoridoriand/multi-arch:latest . multiple platforms feature is currently not supported for docker driver. Please switch to a different driver (eg. "docker buildx create --use")
どうやら現在の docker driver ではマルチアーキテクチャのコンテナをビルドできないようです。指示に書いてあるとおり、 docker buildx create --use を実行します。
$ docker buildx create --use $ ecstatic_roentgen
ランダムな名前でビルド用のコンテナが作成されました。
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8ce5fa2759e8 moby/buildkit:buildx-stable-1 "buildkitd" 6 minutes ago Up 6 minutes buildx_buildkit_ecstatic_roentgen0
確かにbuildkitのコンテナが起動していることが分かります。
再度ビルドコマンドを実行します。
$ docker buildx build --platform linux/amd64,linux/arm64,linux/arm/v7 -t doridoridoriand/multi-arch:latest . WARN[0000] No output specified for docker-container driver. Build result will only remain in the build cache. To push result image into registry use --push or to load image into docker use --load [+] Building 133.1s (9/9) FINISHED => [internal] booting buildkit 7.3s => => pulling image moby/buildkit:buildx-stable-1 6.5s => => creating container buildx_buildkit_ecstatic_roentgen0 0.7s => [internal] load .dockerignore 0.0s => => transferring context: 2B 0.0s => [internal] load build definition from Dockerfile 出力が長いので省略
無事ビルドができたようです。ただ、WARNには、
No output specified for docker-container driver. Build result will only remain in the build cache. To push result image into registry use --push or to load image into docker use --load
と書かれていることから、コンテナのビルド結果はキャッシュにしか残ってないようです。利用するには --push オプションでdocker hubにpushするか、--load オプションでローカルに持ってくるかが必要になるようです。今回は後で別マシンでpullしたいので、docker hubにpushすることにしました。
pushオプションを付けて再度実行したところ、無事にpushされ、単一のイメージタグで、複数のCPUアーキテクチャが利用出来るようになっています。

以下が実際にpushしたdocker imageになります。 multi-arch | Tags
pull&実行
実際に動くか試します。まずはx86-64(amd64)PCで実施します。cpuinfoは
processor : 5 vendor_id : GenuineIntel cpu family : 6 model : 158 model name : Intel(R) Core(TM) i9-8950HK CPU @ 2.90GHz 長いので省略
となっています。コンテナをpullして実行してみます。
$ docker pull doridoridoriand/multi-arch:latest $ docker run -it --rm doridoridoriand/multi-arch:latest 2020-04-12 13:54:31 +0000
無事動きました。
次にARM(arm32v8)マシンで実施します。cpuinfoは
$ cat /proc/cpuinfo processor : 0 BogoMIPS : 166.66 Features : fp asimd evtstrm aes pmull sha1 sha2 crc32 cpuid CPU implementer : 0x41 CPU architecture: 8 CPU variant : 0x0 CPU part : 0xd08 CPU revision : 3
となっています。コンテナをpullして実行してみます。
$ sudo docker pull doridoridoriand/multi-arch:latest $ sudo docker run -it --rm doridoridoriand/multi-arch:latest 2020-04-12 14:06:47 +0000
無事実行できました。
まとめ
Dockerがマルチアーキテクチャをサポートしたことで、IntelやAMDのCPU以外でもDockerコンテナを動かす敷居が低くなりました。AWSで言えば、c系インスタンスとa系インスタンスのハイブリット構成でAPIサーバーを構築することも不可能ではなくなったので、実際に採用するかは別として、アーキテクティングの幅が広がったかと思います。
機会があれば、ミドルウェア等で試してみようと思います。